Yekyung Kim Email Scholar Github Twitter
 Toward faithful and human-centric language models
Toward faithful and human-centric language models

I am a third-year Ph.D. student at the University of Maryland, CLIP Lab, advised by Mohit Iyyer. My research in NLP asks how to evaluate and align language models as everything gets long, from long-context understanding to long-form generation to long-horizon problem-solving. I began my Ph.D. at UMass NLP and later transferred to UMD along with my advisor.
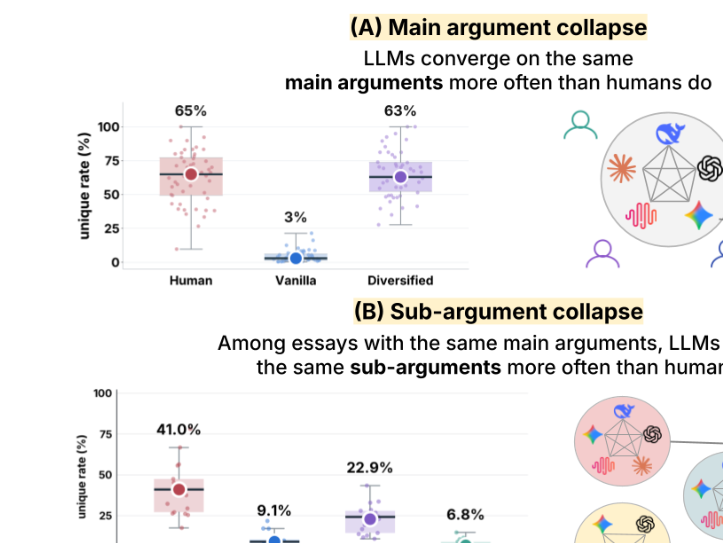
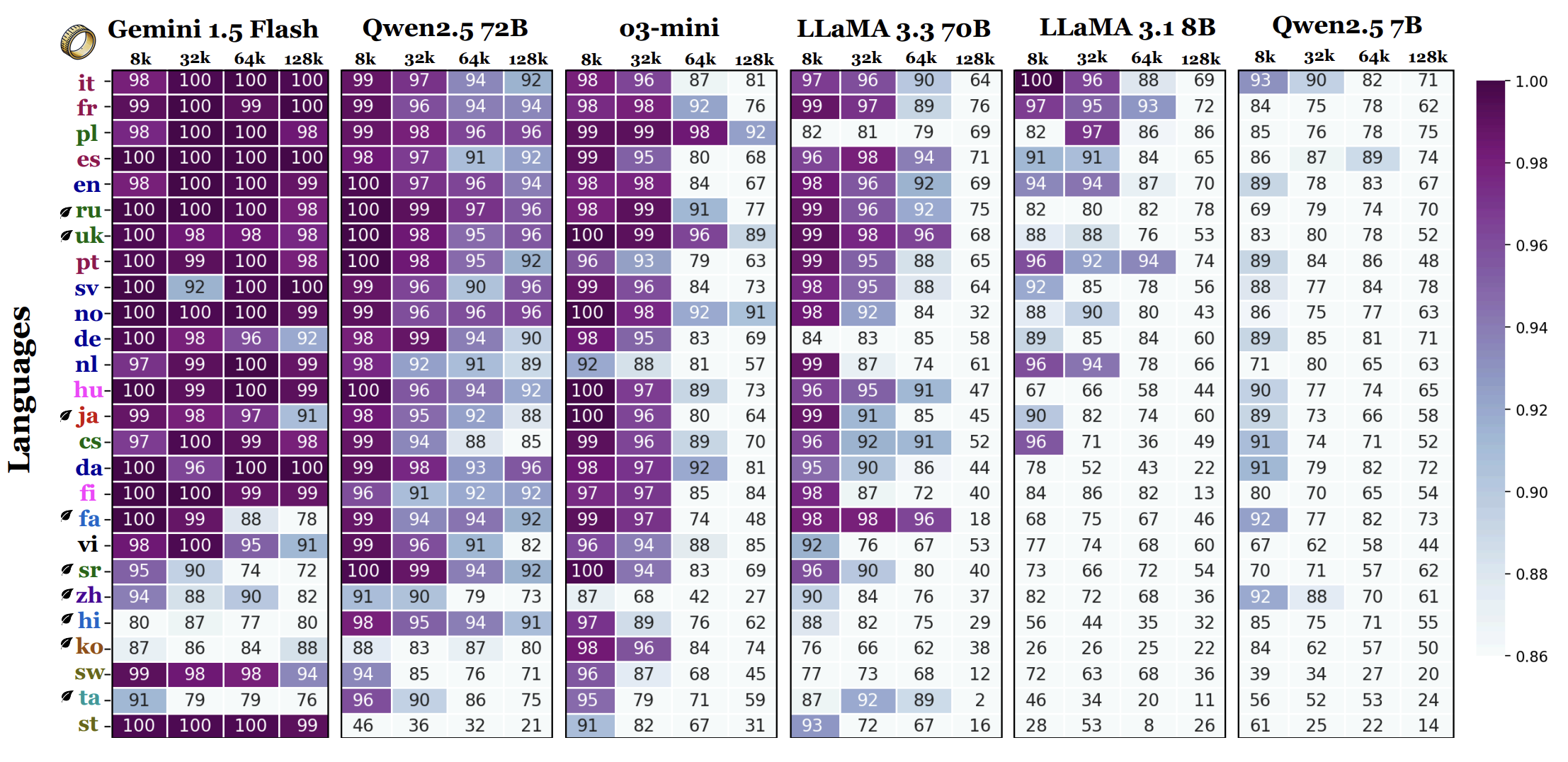
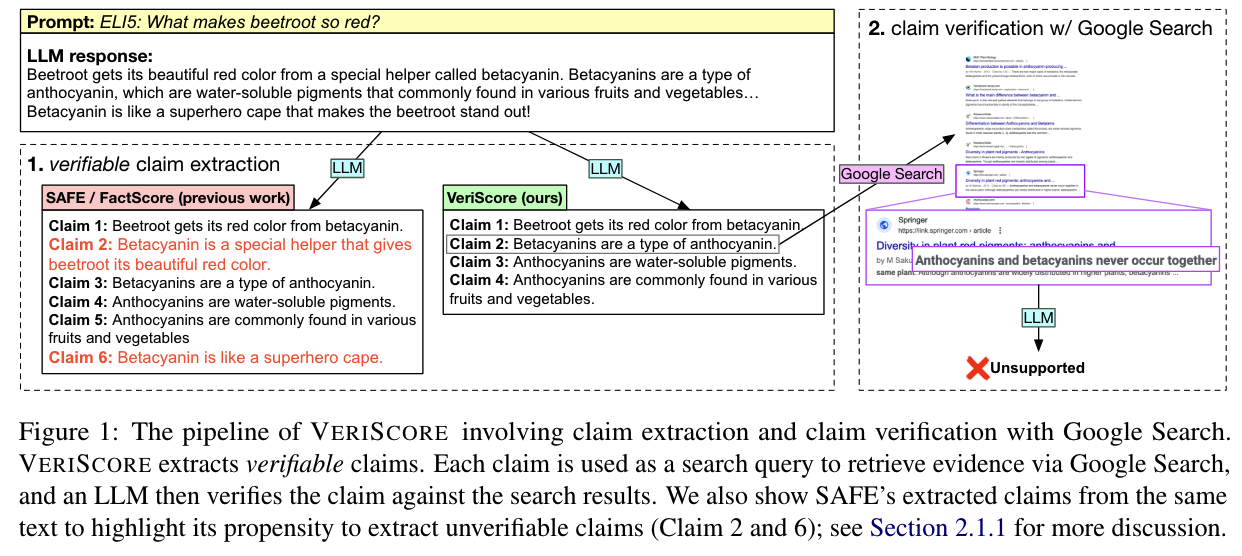
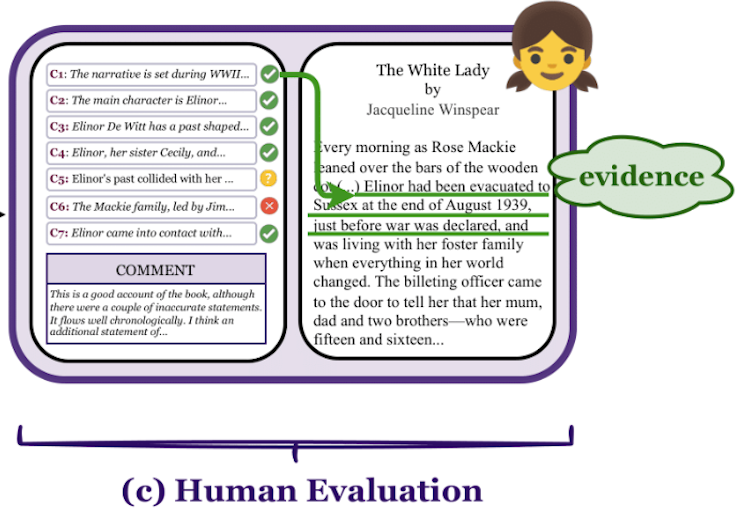
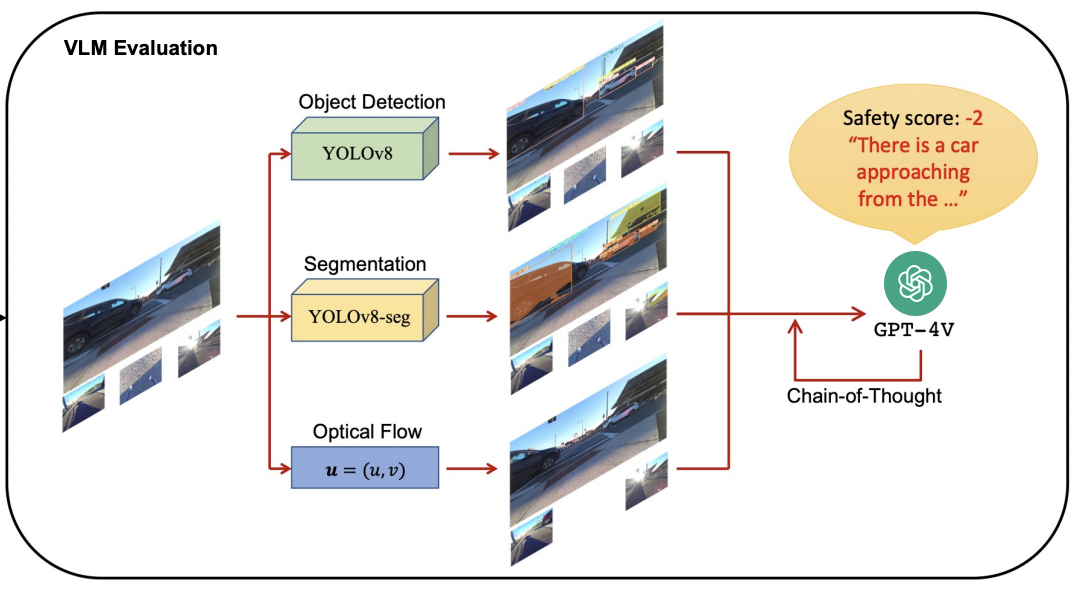
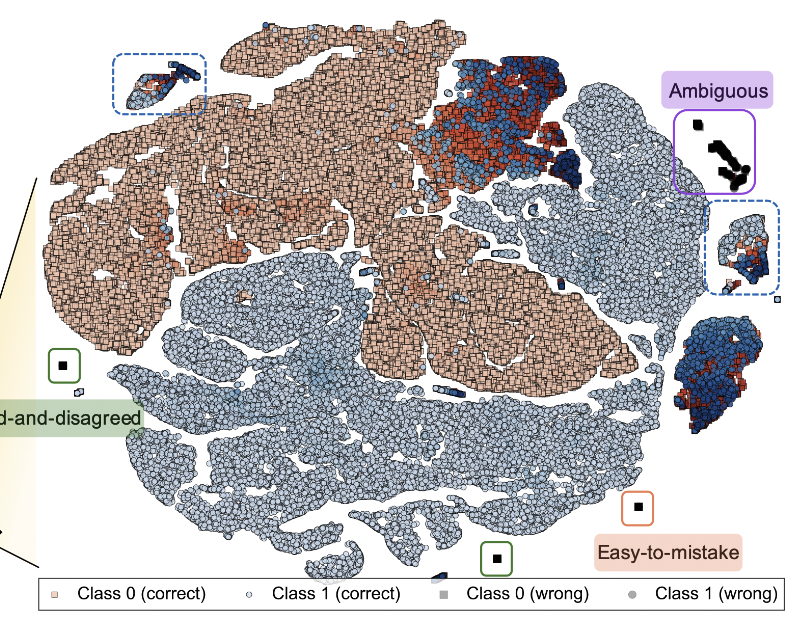
Evaluating faithfulness & factuality in long-context understanding (FABLES, OneRuler) and long-form generation (VeriScore, Argument Collapse).
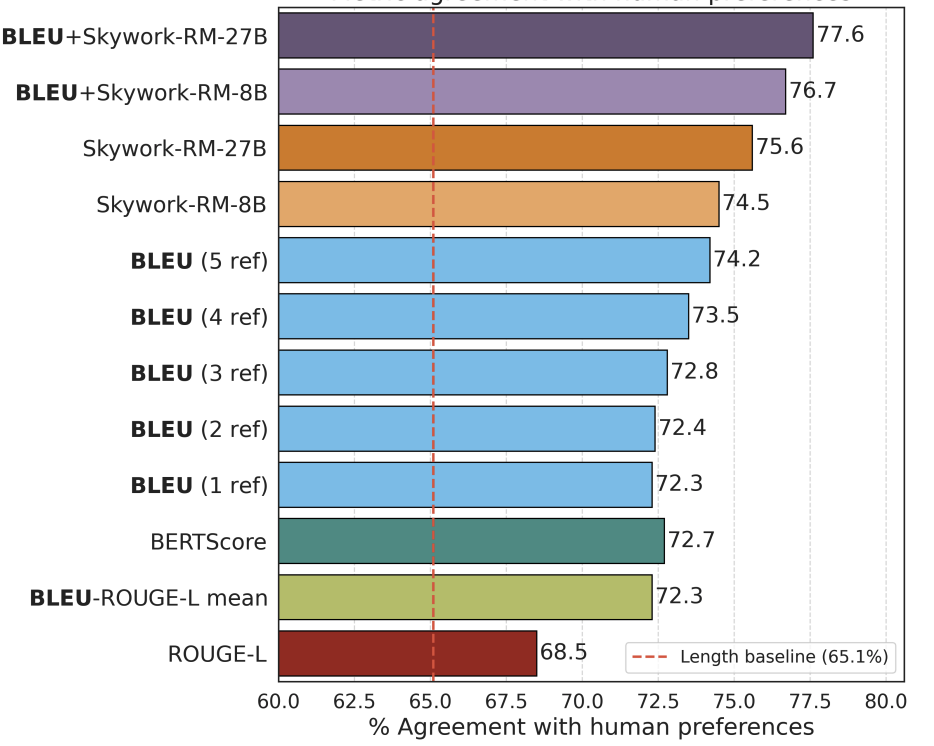
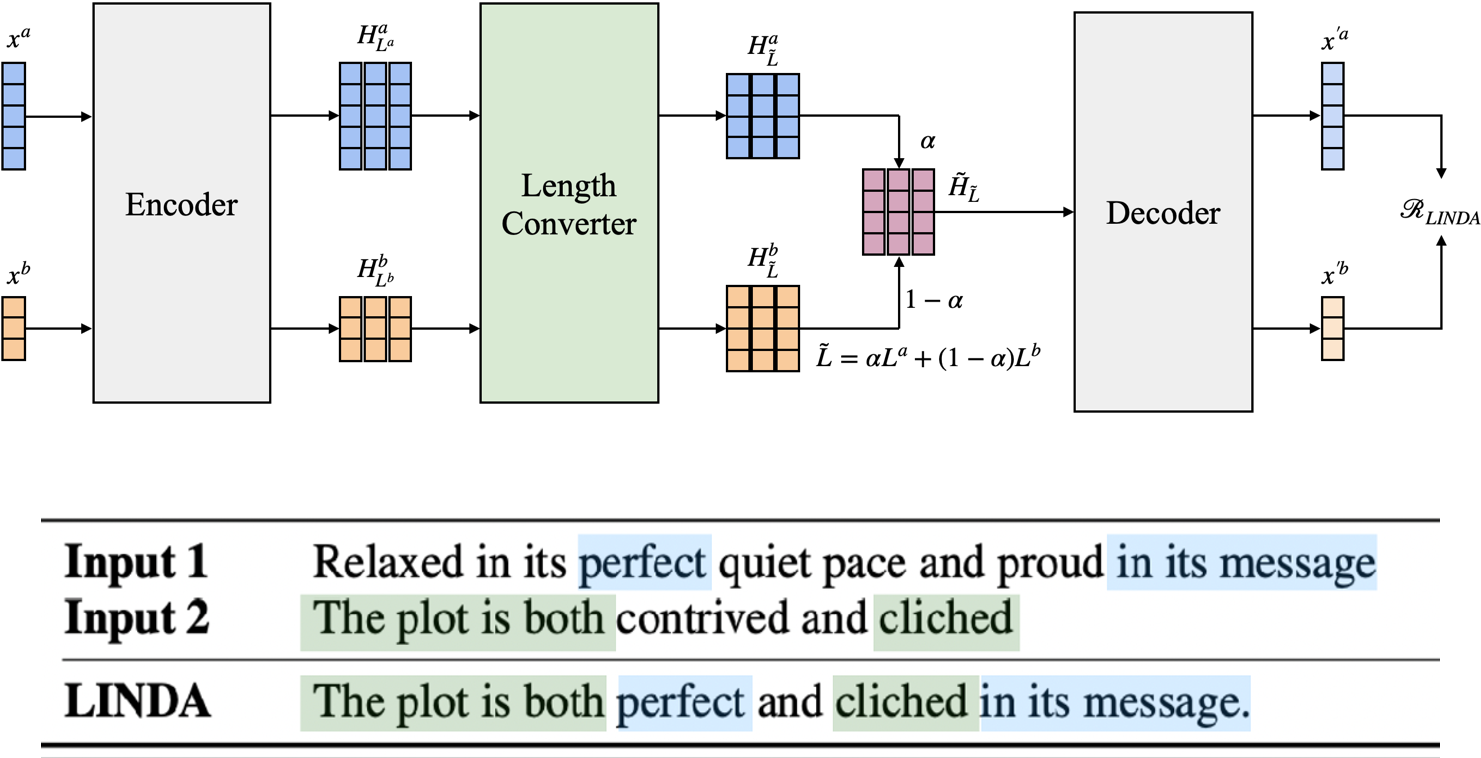
Aligning language models by post-training with synthetic data for instruction following (BLEUBERI) and compositional reasoning.
Before my Ph.D., I worked at Hyundai Motor Group and LG Electronics as a research engineer. I was selected as a specialist in AI and conducted research at CMU LTI as a visiting scientist mentored by Jaime Carbonell.